
2026 has already opened with another high-profile cybersecurity incident in New Zealand’s health sector. ManageMyHealth, a platform used to handle sensitive health and personal information, has reported unauthorized access and is working through investigation and notification steps.
This isn’t the first time New Zealand’s health system has been hit. Recent years have included serious privacy and security failures across the sector, and the pattern is familiar: the public ends up carrying the consequences while organisations scramble to explain how it happened.
It’s tempting to pin incidents like this on “technology” or default to vendor blame. But that framing often dodges the real question: who owned risk, who enforced verification, and who had the authority to stop unsafe practices before they became public incidents? If someone buys a car, ignores the basics of safe driving, and crashes, it’s not automatically the dealer’s fault. Systems and suppliers matter, but outcomes still reflect how responsibility is assigned and how discipline is enforced.
Plenty of failures get blamed on “the system,” “the vendor,” or “the platform.” That’s convenient, because it lets leadership stay clean. The repeat pattern is simpler: unclear accountability, weak verification, confused incentives, and management that substitutes theater for control.

The research still points in the same direction. Recent syntheses of IT project failure factors keep circling back to management and organisational breakdowns: unrealistic or unclear expectations, failure to manage end-user expectations, and poor communication with users and stakeholders (Schmidt, 2023). Even in agile contexts, where “process” is supposedly lightweight, the dark side shows up fast when customer involvement drops and delivery pressure rises, because those conditions cascade into quality and productivity issues (Meckenstock et al., 2024).
Process improvement research says the same thing in plainer terms. A systematic review of process improvement project failures highlights resistance to cultural change, insufficient top management support, inadequate training and education, poor communication, and lack of resources as primary causes (Bader et al., 2023). You can buy better tools. You can’t outsource judgement.
What follows are three live examples that show the same mechanics in different clothes.
ManageMyHealth: When Nobody Owns the Whole Problem
ManageMyHealth reported a “cyber incident” affecting its patient portal, stating that a forensic investigation found that Manage My Health says it became aware of unauthorized access to its New Zealand application on 30 December 2025, after being notified by a partner. It says it moved to secure the platform, engaged independent international forensic consultants, notified the Office of the Privacy Commissioner and Police, and began work to identify affected users (ManageMyHealth, 2026a).
By 2 January 2026, it stated that approximately 7% of its roughly 1.8 million registered patients may have been affected, and that preliminary findings indicate access was limited to a specific group of documents. It also stated there was no evidence at that stage that the core patient database was accessed, no evidence of data modification or destruction within its system, and no access to user credentials (ManageMyHealth, 2026b). RNZ reporting captures the operational consequence: clinicians and patients are stuck in a trust gap while they wait for clarity on scope, and the public conversation becomes part of the incident response whether the organization wants it or not (Radio New Zealand, 2026).
What went wrong, based on what’s been disclosed so far, isn’t “technology” in the abstract. The visible failure mode is organizational.

First, the fact that Manage My Health says it learned about the incident from a partner points to a detection and escalation chain that may not have surfaced the event internally first. That matters because modern incident guidance treats detection, escalation, and cross-stakeholder coordination as governance outcomes, not just security tooling (NIST, 2024; NIST, 2025).
Second, the company’s own messaging emphasizes how complex it is to identify affected users, and RNZ reports GPs raising concerns about limited information early in the event. That combination usually signals that data classification, logging, and “who had access to what” traceability weren’t already packaged into a ready-to-run response workflow. In healthcare, that lag is costly because privacy concerns can directly suppress patient disclosure and engagement, which then degrades care quality and trust (Iott et al., 2020; Aldosari, 2025). More bluntly: when an organization can’t rapidly answer “what was accessed, by whom, and who is impacted,” the incident isn’t contained from the user’s perspective, even if the attacker is no longer inside.
Finally, we still don't have a clear picture of which people are directly responsible for these oversights. ManageMyHealth is the owning organization, but who exactly created this mess, and what is being done to hold them accountable? Major governance failures are a legitimate cause for discipline.
What should’ve happened looks boring, and that’s the point.
Research on cyber incidents keeps landing on the same operational truth: response quality is mostly predetermined by what you built and rehearsed before anything goes wrong. Tabletop and discussion-based exercises are consistently used to test incident response readiness, expose coordination gaps, and surface weaknesses in systems, processes, and human decision-making under pressure (Alinier et al., 2023; Angafor et al., 2024).
Once an incident starts, organizations also need structured reporting and logging that captures more than “major breaches,” because near-misses and weak controls are often the signals that would have prevented the next escalation. Safety-informed cybersecurity research explicitly argues for incident reporting systems that include noncritical events such as near misses, and it highlights practical design needs like clear channels, nonpunitive reporting, and feedback loops so reports turn into corrective action (Ebert & Dittmann, 2025).
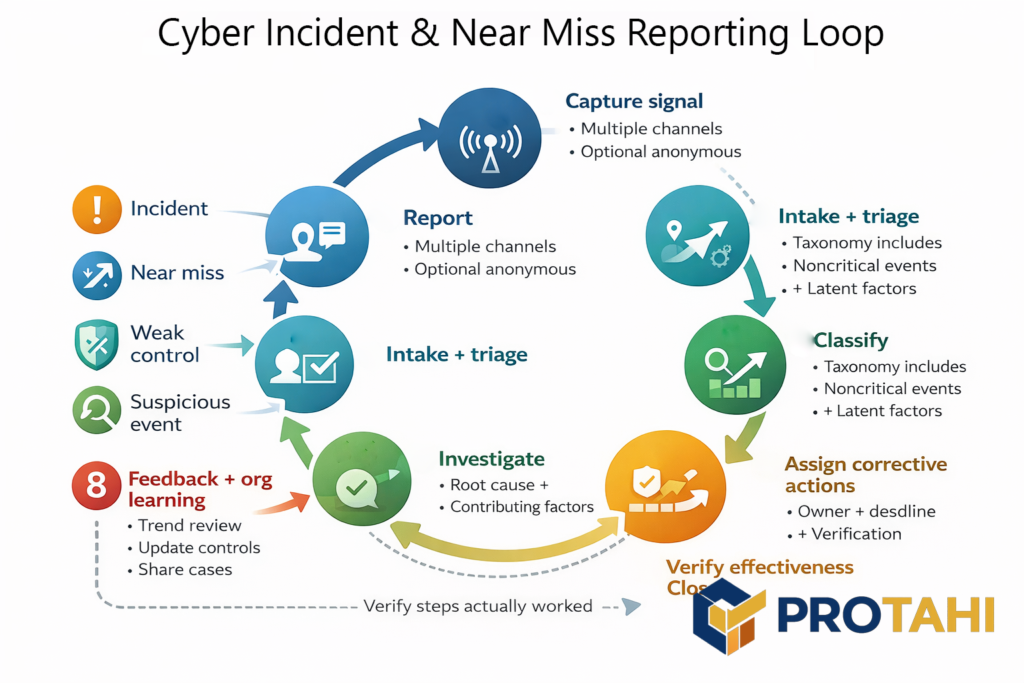
The reason this matters is simple: without disciplined reporting and post-incident learning, organizations repeatedly miss the chance to implement lessons, evaluate whether fixes work, and actually reduce recurrence. A 2023 systematic review on organizational learning from cybersecurity incidents found exactly those failure patterns: superficial causal investigations, scarce effort to implement lessons, and little evaluation of whether changes reduce future incidents (Patterson et al., 2023). Put together, the evidence supports the management claim: you don’t “handle” a breach with tools. You handle it with rehearsed decision rights, reliable reporting, and a learning loop that leadership actually enforces.
In practice, that means an organization running a patient portal should already have decision rights nailed down before anything happens: who can shut off integrations, who owns notification thresholds, who speaks publicly, and how clinical stakeholders are briefed early so they’re not learning from the news.
The deeper lesson is that identity, privacy, and communications can’t be treated as separate workstreams. If identity and access controls are governed as “IT configuration,” privacy is governed as “legal compliance,” and communications is governed as “brand management,” you get a predictable failure: a real incident forces these domains into one moment, and they collide instead of converging. Healthcare breach research repeatedly frames cybersecurity events as risk management issues with operational disruption, reputational impact, and downstream patient consequences, which is why response quality is inseparable from management maturity (Dolezel & McLeod, 2023; Pool et al., 2024).
This is also why crisis communication in healthcare breaches is treated in the literature as a structured organisational requirement, not an optional PR layer after technical containment (Looi et al., 2024).
Nothing here requires exotic technical explanations to diagnose. The visible pain is what happens when identity and access risk, privacy obligations, and crisis comms are run as separate domains instead of one managed system with a single accountable owner. That gap is management, not tooling.
Deloitte: This wasn’t “AI risk.” It was Bad Management. Twice.
Deloitte’s Australia incident got attention because the failure was obvious and documentable. A report for Australia’s Department of Employment and Workplace Relations went out with fabricated academic references and a made-up quote attributed to a Federal Court judgment. Deloitte later agreed to repay the final instalment of the contract, and the department’s own resource page states the report was updated on 26 September 2025 to correct references and footnotes, replacing the earlier version. (Associated Press, 2025; Department of Employment and Workplace Relations, 2025; The Guardian, 2025).

Then the pattern showed up again in Canada. Newfoundland and Labrador commissioned Deloitte to produce a Health Human Resources Plan, and reporting later highlighted citations that appeared not to exist. Coverage reports the province directed Deloitte to review the citations, Deloitte acknowledged the cited items were incorrect while standing by its findings, and the work was described as costing about $1.6 million. (The Canadian Press, 2025; CityNews, 2025; The Independent, 2025).
Ever hear the saying "Where there's smoke, there's fire?" It must be getting pretty hot over at Deloitte right now. Getting caught twice inside of a four month period doing the same thing isn't an accident. It's bad management being exposed. Outside of the company nobody really knows what went on here, and what decisions and conversations led up to this series of issues. But one thing is clear. Deloitte has a problem on their hands, and this is likely only the beginning.
Here’s the point that matters for leaders. Calling this a “controls problem” is too charitable, because controls don’t fail on their own. Management chose a delivery posture where evidence integrity wasn’t treated as production-critical. Somebody decided it was acceptable for public-facing, policy-adjacent deliverables to ship not once, but at least twice, without a hard verification step that could block release. That decision might have been driven by margin, deadlines, internal utilization targets, or simple arrogance, but the mechanism stays the same: if leadership doesn’t force verification, the organization learns that plausibility beats accuracy.
Now if you’re thinking Deloitte is alone here, think again. 2025 was the year major consultancies normalized AI-assisted authorship across the actual production workflow: McKinsey pushed its internal gen-AI platform “Lilli” into day-to-day consulting work, including drafting proposals and accelerating slide production at scale (McKinsey, 2023; Bloomberg, 2025).
PwC moved even more directly by rolling out ChatGPT Enterprise across tens of thousands of staff in the US and UK, explicitly positioning it as a firmwide productivity lever (PwC, 2024; Reuters, 2024). BCG has built internal tools aimed at exactly the same thing, speeding up knowledge retrieval, communications, and deck creation, and it’s simultaneously documenting how pervasive GenAI usage has become in professional services work (Business Insider, 2025; BCG, 2025).
That “use AI and produce more” posture becomes a problem because it changes the failure mode of consulting work: instead of slow errors that get caught in human drafting friction, you get fast, plausible output that can slide through weak review and land in front of executives and ministers wearing the implied authority of a top-tier brand. When evidence trails and citation integrity aren’t treated as production-critical, AI just amplifies the existing bad habit: shipping confidence before verification. That’s why AI governance frameworks keep hammering the same point: you can’t scale use without scaling accountability, oversight, and traceable controls, because the risk isn’t just wrong text, it’s wrong decisions made confidently and at speed (ISO, 2023; NIST, 2023)
This is what “use AI and produce more” looks like when it leaks into real work. You don’t get one hallucinated footnote, you get a pipeline that normalizes speed-first drafting and turns review into a cosmetic pass. Deloitte’s own public-facing remediation, including the issuance of revised versions after scrutiny, reinforces that the checking happened after reputational damage, not before publication. (Department of Employment and Workplace Relations, 2025; Financial Times, 2025; Australian Financial Review, 2025).
If you want the management lesson in one line: a firm didn’t “make an AI mistake,” it ran a practice where nobody with authority was required to prove the work was true before selling it as trustworthy.
Structural Governance and Capacity Debt in New Zealand's Healthcare Data Breaches
New Zealand’s health sector hasn’t had a single “bad breach.” It’s had a pattern: the Waikato DHB ransomware event in 2021 included real-time doxxing, then national-level Te Whatu Ora incidents including the COVID-19 data leak scoped at 12,000+ people (reported February 2024), and later a staff occupational health and safety breach tied to an October 2024 incident (reported March 2025). (Radio New Zealand, 2021; Radio New Zealand, 2024; Radio New Zealand, 2025). Layer on top the pause/deferral of 136 data and digital projects and you’re looking at a system that’s been repeatedly asked to carry high-trust digital services while stabilization work gets delayed or cut. (Radio New Zealand, 2024).
Timeline of New Zealand's Healthcare Leadership Failures
| Year | Agency | Incident |
| 2021 | Waikato DHB | Ransomware attack |
| 2021 | All Local DHB | Consolidation into Health NZ |
| 2024 | Health NZ / Te Whatu Ora | Data Breach affects over 12,000. |
| 2024 | Health NZ / Te Whatu Ora | Malicious Actor downloads staff data. |
| 2024 | Health NZ / Te Whatu Ora | Financial Mismanagement |
| 2024 | Health NZ / Te Whatu Ora | Capacity Debt stops 136 projects |
| 2024 | Health NZ / Te Whatu Ora | Weak data governance |
| 2025 | Health NZ / Te Whatu Ora | IT Staffing shortfalls reported |
| 2025 | Health NZ / Te Whatu Ora | Massive software fragmentation |
This is not just “more risk.” It’s compounding debt, policy, and management theatrics. Research has a name for it: security debt and organizational learning failure. When capacity, maintenance, and prevention work gets deferred, risk accumulates quietly until it surfaces as incidents. Security debt literature describes exactly this pattern: vulnerabilities and weak controls pile up under delivery pressure and resourcing constraints, then show up later as expensive failures (Kruke & Kasauli, 2024). And when organizations don’t run strong learning loops after incidents, they repeat the same mistakes, because fixes stay shallow and evaluation is weak. (Patterson et al., 2023). In healthcare, that’s worse than embarrassment. It disrupts care delivery and corrodes patient trust in disclosure and access pathways. (Aldosari, 2025).
The governance link is the point. You don’t get high-uptime, high-security, high-trust services by accident. You get them when leadership protects stabilization capacity, enforces decision rights, and treats prevention as a rewarded outcome rather than a budget line that can be raided.
This isn't How it's Supposed to Work
This isn’t a call for more process. It’s a call for fewer ceremonies, and more accountability. Because there is a consistent theme in all of these scenarios: Negligence. People can and do run complex technology environments that are capably led every day. If this type of dysfunction exists in your organization, it's a clear sign of a leadership problem, and likely an accompanying culture problem.
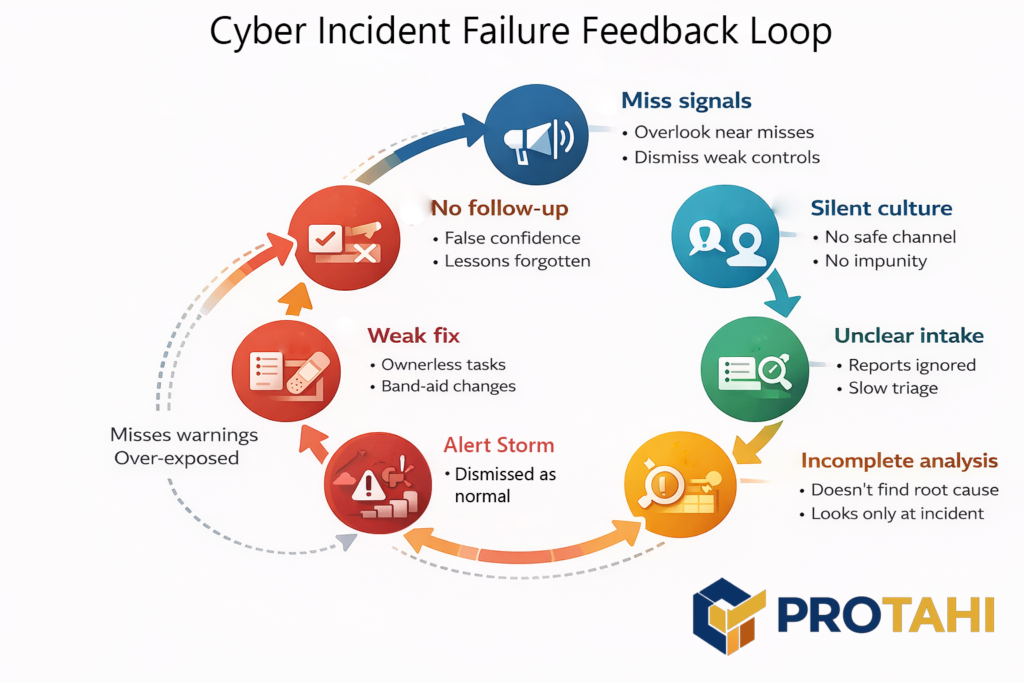
If leaders reward “green status” and punish bad news, teams will hide reality until it explodes. That’s not culture fluff, it’s a control failure. The failure literature repeatedly points to miscommunication, misaligned expectations, and weak management practices as drivers of project collapse. (Lehtinen et al., 2014; Antony, 2019).
Provide Accountability, not Excuses
After Deloitte delivered the aforementioned Australian government-commissioned report, then agreed to refund the final instalment of its A$440,000 contract once the issues were exposed, nobody should be tolerating excuses like “AI is new” or “quality slipped.” That outcome is a management failure. It happens when leadership pushes throughput faster than verification, and when nobody with real authority is forced to prove the work is traceable before it inherits the implied credibility of a top-tier brand. (Associated Press, 2025; The Guardian, 2025; Financial Times, 2025; Australian Financial Review, 2025).
Health NZ then disclosed that a “malicious actor” accessed and downloaded private information about current and former staff, linked to an October 2024 security incident, which makes any “one-off” framing unserious. (Radio New Zealand, 2025; 1News, 2025). Separately, Manage My Health has reported unauthorized access to its New Zealand application, said it engaged independent forensic support, and put early scope estimates at 6–7% of approximately 1.8 million registered users while investigation continued. (Manage My Health, 2026; Radio New Zealand, 2026). Whatever each final forensic narrative becomes, the public fact pattern is already clear: critical health-adjacent systems keep failing in ways that force patients, staff, and clinicians to carry uncertainty and risk in real time.

So the response can’t be another round of ceremonies. It can’t be “new frameworks,” “lessons learned,” and glossy assurance language that changes nothing. Research on organizational learning from cybersecurity incidents shows the recurring failure mode: shallow learning, weak follow-through, and poor evaluation of whether corrective actions actually reduce recurrence. That’s why theatre persists. It produces artifacts, and glossy flow charts that defer accountability, not outcomes. (Patterson, Nurse, & Franqueira, 2023).
Accountability means consequences and enforced discipline: named owners with authority, deliverables that don’t ship without evidence traceability, incident response owned at executive level because the decisions are managerial, and oversight that has teeth rather than being satisfied by compliance checkmarks. If leadership can’t show what changed after each incident and explicitly state why recurrence risk is lower now, they haven’t earned trust. They’ve written another story about why it wasn’t their fault.
What's Our Stake?
Protahi’s angle here is blunt: organisations don’t need more frameworks, they need operators with the mandate to make decisions stick, and the integrity to not point at somebody else and try to make it their problem. Accountability starts at the top, and we have a track record of integrity, not being afraid of bad news, and aggressively pursuing timely resolutions that don't involve endless PowerPoint training sessions and catered lunches.
Our work looks like embedded leadership that can own delivery rhythm, enforce verification, run incident readiness, and keep cross-functional teams aligned when incentives start to fracture, because that's what it is.
Most places have plenty of process. What they’re short on is experienced, hands-on management that treats outcomes as real, measurable liabilities and treats staff as responsible players in making outcomes happen.
Why do I in particular, as Principal Consultant, have a bone to pick with this type of management? I ran a high security Healthcare IT environment for 10 years in the San Francisco Bay Area. I designed the architecture, processes, and methodologies from top to bottom. I ran the support teams that kept it running. We never had a security breach during that time. We weren't hiding out in some small town nobody has ever heard of. We were in the heart of Silicon Valley, and had zero trust issues despite being a small team.
It's my business to call this out. We can and should be doing better.